Machine Learning pipeline
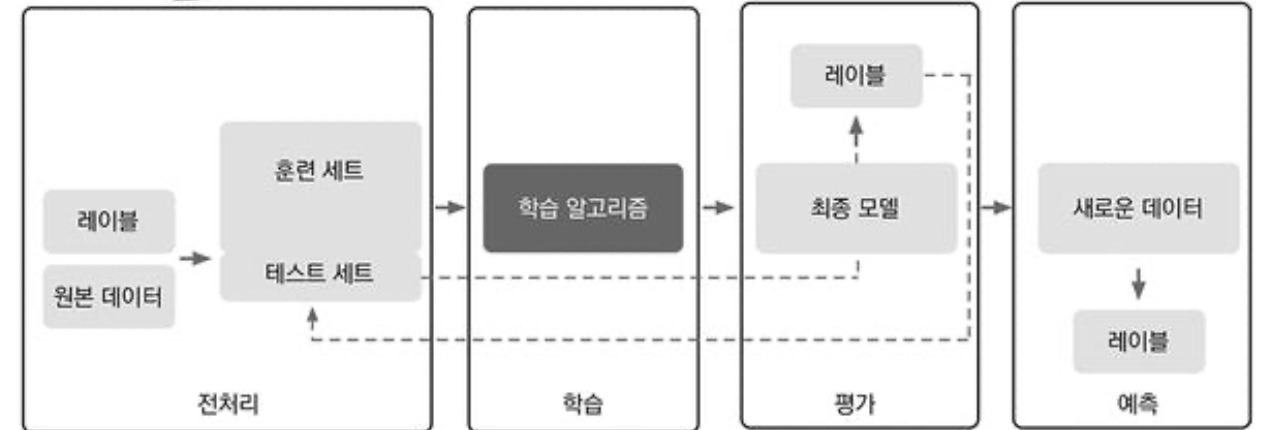
전처리: 데이터 형태 갖추기
주어진 원본 데이터의 형태와 모습이 학습 알고리즘에서 최적에 성능을 낼 수 있게 조정
많은 머신 러닝 알고리즘에서 최적의 성능을 내기 위해서는 선택된 특성이 같은 스케일을 가져야 한다.
특성을 [0,1] 범위로 변환하거나 표준 정규 분포(standard normal distribution)으로 변환하는 경우가 많다.
일부 선택된 특성이 매우 상관관계가 높아 어느 정도 중복된 정보를 가지고 있다면, 차원 축소 기법을 이용해서
특성을 저차원 부분 공간으로 압축할 수 있다.
차원 축소를 통해 더 빨리 알고리즘을 실행할 수 있으며, 어떤 경우에는 차원 축소 모델의 예측 성능을 높이기도 함.
머신 러닝 알고리즘 훈련 데이터 셋이 잘 작동하는지, 새로운 데이터에서도 잘 일반화 되는지 테스트 하기 위해서
훈련 데이터셋과 테스트 데이터셋을 나누고 테스트 셋을 별도로 보관하다가 최종 모델을 평가하는데 사용한다.
데이터셋에 관련 없는 특성(또는 잡음)이 매우 많은 경우, 즉 신호 대 잡음비(Signal-to-Noise Ratio, SNR)이 낮은 경우를 말한다.
예측 모델 훈련과 선택
여러 머신 러닝 알고리즘이 존재하며, 이들은 각기 다른 문제를 해결하기 위해 개발되었다.
따라서 현실에서 가장 좋은 모델을 훈련하고 선택하기 위해서는 최소한 몇 가지 알고리즘을 비교해야 한다.
이 때 비교를 위한 성능을 측정할 지표를 먼저 결정해야 하는데, 분류에서 널리 사용되는 지표는 정확도(accuracy)이다.
테스트 데이터셋과 실제 데이터에서 어떤 모델이 잘 작동하는 알기 위해서 교차 검증 기법을 사용한다.
교차 검증 기법을 위해 전처리 과정에서 나누었던 훈련 데이터셋을 훈련 데이터셋과 검증 데이터셋으로 더 나눈다.
그 외에도 하이퍼 파라미터(hyperparameter) 최적화 기법을 많이 사용한다.
모델을 평가하고 본 적 없는 샘플로 예측
훈련 데이터셋에서 최적의 모델을 선택한 후에 테스트 데이터셋을 사용하여, 이전에 본 적이 없는 데이터에서
얼마나 성능을 내는지 예측하여 일반화 오차를 예상한다. 만일 만족스러운 성능을 얻었다면, 모델을 선택하고
특성 스케일 조정과 차우너 축소 같은 단계에서 사용한 파라미터는